This article is going to hash out some interesting question which is also one of the favorite questions asked in SQL Server interviews. Hope, you guys got it. J
Yeap, you are right that is “Find out Nth highest salary of employee”.
In the interviews, we used to get many answers for this questions like using CURSORS, Sub Query etc., which is involved lot of SQL statements with low performance.
This can be achieved very easily by using RANK()or DENSE_RANK()functions which were first introduced in SQL Server 2005. It may be old function but it’s worth of sharing. J
Let us create sample table with few records for this demo.
CREATE TABLE [DBO].[Employee]
(
[EmpCode] INT IDENTITY (1,1),
[EmpName] VARCHAR(100) NOT NULL,
[Salary] NUMERIC(10,2) NOT NULL,
[DeptName] VARCHAR(100) NOT NULL
)
GO
(
[EmpCode] INT IDENTITY (1,1),
[EmpName] VARCHAR(100) NOT NULL,
[Salary] NUMERIC(10,2) NOT NULL,
[DeptName] VARCHAR(100) NOT NULL
)
GO
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Priya’,60000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Chaitu’,55000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Praveen’,35000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Sathish’,57000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Ramana’,62000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Kiran’,75000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Krishna’,78534,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Sravani’,23000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Mahesh’,23500,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Raman’,45000,‘Accounts’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Raghu’,35250,‘Accounts’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Noha’,27000,‘Sales’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Sushma’,29500,‘Sales’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Sekhar’,30000,‘Sales’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Ravi’,30000,‘Sales’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Harini’,35000,‘Sales’);
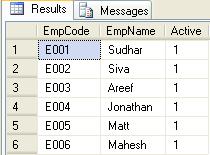
Hope, successfully the above statements were executed and the records are inserted into [Employee]table.
Let us execute the below query to check the inserted records:
SELECT
[EmpCode],[EmpName],[Salary]
FROM
[DBO].[Employee] WITH (NOLOCK)
GO
[EmpCode],[EmpName],[Salary]
FROM
[DBO].[Employee] WITH (NOLOCK)
GO
The output would be as shown below :
Now, the question is to display 4th highest salary of employee. Before that let us execute and find manually what is the 4th highest salary in the table using the following query.
SELECT
[EmpCode],[EmpName],[Salary]
FROM
[DBO].[Employee] WITH (NOLOCK)
ORDER BY
[Salary] DESC
GO
[EmpCode],[EmpName],[Salary]
FROM
[DBO].[Employee] WITH (NOLOCK)
ORDER BY
[Salary] DESC
GO
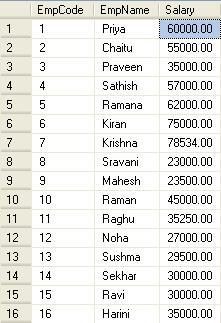
The output would be as shown below :

Now, let us find out the 4th highest salary of employee using RANK()function:
As we have seen from the above output, the fourth highest salary is “60000” of employee “Priya”, let us execute the below SQL statement and confirm whether it gives the same output.

SELECT
[EmpCode],[EmpName],[Salary]
FROM( SELECT
[EmpCode],[EmpName],[Salary]
,RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = 4
GO
[EmpCode],[EmpName],[Salary]
FROM( SELECT
[EmpCode],[EmpName],[Salary]
,RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = 4
GO
Yeap, this is what we expected right. J

Let me add few more records for other scenarios where we may not use RANK()function, for this example let us insert few more records.
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Yash’,60000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Bhaskar’,60000,‘Accounts’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Swetha’,75000,‘IT’);
INSERT INTO [DBO].[Employee] ([EmpName],[Salary],[DeptName]) VALUES (‘Shailaja’,45000,‘Sales’);
Just execute the below query to check the inserted records:
SELECT
[EmpCode],[EmpName],[Salary]
FROM
[DBO].[Employee] WITH (NOLOCK)
GO
[EmpCode],[EmpName],[Salary]
FROM
[DBO].[Employee] WITH (NOLOCK)
GO
Now, again the question is to display 4th highest salary of employee. Before that let us execute and find manually what is the 4th highest salary in the table using the following query.

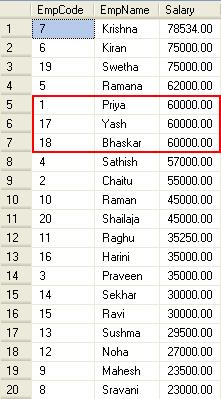
As we know the 4th highest salary is “60000”and there are three employees having the same salary. Let us execute the above query and check the result now.
SELECT
[EmpCode],[EmpName],[Salary]
FROM( SELECT
[EmpCode],[EmpName],[Salary]
,RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = 4
GO
[EmpCode],[EmpName],[Salary]
FROM( SELECT
[EmpCode],[EmpName],[Salary]
,RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = 4
GO
The output would not be as we expected. L

Let us execute the same query with including [Highest] column in the SELECT statement.
SELECT
[EmpCode],[EmpName],[Salary],[Highest]
FROM
(
SELECT
[EmpCode],[EmpName],[Salary]
,RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
GO
[EmpCode],[EmpName],[Salary],[Highest]
FROM
(
SELECT
[EmpCode],[EmpName],[Salary]
,RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
GO
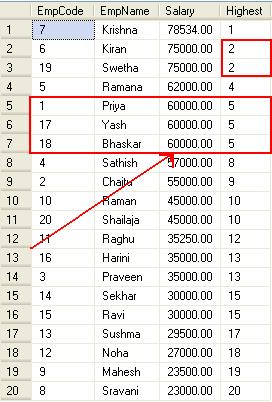
From the above query output, we can understand that “60000” salary is went to 5th position, It’s because If two or more rows tie for a rank, each tied rows receives the same rank.
Also, you can see, it’s skipped the 3rd position because there are 2 guys in 2nd position.
I know what you are thinking, you do not want to skip any position even in tied situation. Am I right? J
Yeap, For this kind of situation we can go for DENSE_RANK()function.
Let us execute the same query with replacing DENSE_RANK() function instead of RANK().
SELECT
[EmpCode],[EmpName],[Salary],[Highest]
FROM
(
SELECT
[EmpCode],[EmpName],[Salary]
, DENSE_RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
GO
[EmpCode],[EmpName],[Salary],[Highest]
FROM
(
SELECT
[EmpCode],[EmpName],[Salary]
, DENSE_RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
GO

From the above query output, you can understand even the values are tied, it is giving rank without any gaps.
Now, let us execute the below statement to find again the 4th highest though we know it is “60000”.
SELECT
[EmpCode],[EmpName],[Salary]
FROM
[EmpCode],[EmpName],[Salary]
FROM
( SELECT
[EmpCode],[EmpName],[Salary]
, DENSE_RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = 4
GO
[EmpCode],[EmpName],[Salary]
, DENSE_RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = 4
GO

Yeap, we got the same result as we expected. J
The same query can be modified slightly , so that we can identify the Nth highest salary of employee.
The below query will give us the 2nd highest salary of employee. If you want, you can change the value and execute. J
DECLARE @iHightest INT
SET @iHightest = 2
SELECT
[EmpCode],[EmpName],[Salary]
FROM
(
SELECT
[EmpCode],[EmpName],[Salary]
, DENSE_RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = @iHightest
GO
[EmpCode],[EmpName],[Salary]
FROM
(
SELECT
[EmpCode],[EmpName],[Salary]
, DENSE_RANK() OVER (ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = @iHightest
GO
The output would be :


Sometime, we may need to find out Nth highest salary of each department. Here, we go. J
DECLARE @iHightest INT
SET @iHightest = 2
SELECT
[EmpCode],[EmpName],[Salary],[DeptName]
FROM
(
SELECT
[EmpCode],[EmpName],[Salary],[DeptName]
, DENSE_RANK() OVER (PARTITION BY [DeptName] ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = @iHightest
ORDER BY
SET @iHightest = 2
SELECT
[EmpCode],[EmpName],[Salary],[DeptName]
FROM
(
SELECT
[EmpCode],[EmpName],[Salary],[DeptName]
, DENSE_RANK() OVER (PARTITION BY [DeptName] ORDER BY [Salary] DESC) AS [Highest]
FROM
[DBO].[Employee] WITH (NOLOCK)
) AS High
WHERE
[Highest] = @iHightest
ORDER BY
[DeptName]
GO
GO
The output would be :

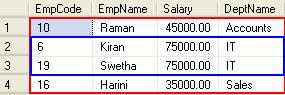
From the above result, we could get the 2nd highest salary for each department. Have you noticed that in the SQL statement I have used PARTITION BY clause
Which divides the result set produced by the FROM clause into partitions to which the DENSE_RANK()function is applied.
Hope, you have enjoyed reading this article and share your comments. J
Note :
- RANK()or DENSE_RANK()will work in SQL Server 2005 and above versions.
- For more info refer http://msdn.microsoft.com/en-us/library/ms173825